Proposal for a Network of Ideas
Jonathan Riehl
The Wild Idea Preserve
-
Introduction.
The Network of Ideas is meant to contain and reference
large amounts of human language-based data. The Network of Ideas
is essentially a graph data structure that will allow machines to manipulate
and present human language data in a variety of ways. The graph will
consist of elements that both implicitly and explicitly have directed edges
to other elements of the knowledge base. Clients of the knowledge
base will be able to perform various operations on these elements for the
purpose of knowledge discovery and presentation.
-
Elements and Compounds.
An element is a unique datum or conceptual atom
in the knowledge base. A collection of element instances may be considered
to be a compound. There are various compound types defined in this
proposal, each with specific data manipulation purposes.
-
Data Types.
Elements in the idea space rely upon three basic
data structures: the unique identifier, the list, and the map.
-
The unique identifier is a numerical value represented by a positive integer.
Each element in the knowledge base has a unique identifier.
-
A list is an ordered collection of unique identifiers. Each element
is considered to have some form of definition or content that is represented
by a list.
-
The final data type used by the knowledge base is a map. The map
allows a one to one mapping from one unique identifier to another.
-
Operations.
The knowledge base defines several basic operators
upon elements and compounds (various collections of elements.) These
operators provide a means for creation and navigation of a knowledge base.
-
Viewers and Editors.
Employing the operations defined for elements and
compounds, viewers and editors are the primary tools for interfacing with
the knowledge base. By using several patterns of construction and
navigation, viewers and editors may maximize the automation of knowledge
discovery and compression.
-
Elements and Compounds
-
An Introduction to Idea Pool Elements and Compounds
-
Atoms.
Atoms (a.k.a. elements) are the basic building block
of the knowledge base. Atoms represent human concepts that are enumerated
using unique identifiers [McConnell]. Atoms
are considered to have a definition, represented by the list data type,
and attributes, represented by the map data type.
-
Dimensions.
Dimensions are collections of atoms that form an
ordered list of atoms. This is in contrast to the ordered list of
unique identifiers. Atoms that compose a dimension must share certain
attributes and involve special reference atoms.
-
Trees.
Trees are collections of atoms that form a hierarchy
of conceptual information. Each member atom of a tree references
a parent, while the definition of each atom is the vector of its children.
This compound is not required for the basic operation and navigation of
a knowledge space, but is included for utility and completeness.
-
Dictionaries.
Dictionaries are collections of atoms that form
a data structure that is known as a trie. Dictionaries are used to
map lists of unique identifiers onto another unique identifier (and hopefully
an atom in the global space.)
-
Spaces.
A space is defined as a set of one or more atom
instances. A closed space is a space that has an atom instance for
every unique identifier contained by the set of atoms (i.e. the UIDs found
in the atom description and map.) Conversely, an open space is a
set of atoms that contain unique identifiers that have no corresponding
enumerated atom in the space. A global space is a set of all atom
instances in a knowledge base. A subspace of a space is the same
as a subset of the atoms contained by the originating space.
-
Atom Characteristics
The following illustration shows a UML-like [UML]
representation of the atom and its contents:

-
The Atom Identifier.
The atom identifier is a unique identifier number.
For any given space of atoms, no two instances may share the same unique
identifier.
-
The Atom Definition.
The atom definition is an ordered list of unique
identifiers that is used to convey a linear message about the concept.
-
The Atom Attributes.
The atom attributes are used to cross reference
atoms and create contextual information about a given concept.
-
Reserved Atoms.
The following atoms are reserved for every knowledge
base. These atoms are required for basic operation or in use for
a documented compound.
-
NIL
NIL represents the empty set or is used as a terminal
unique identifier for some compounds. The NIL atoms unique identifier
is zero (0.)
-
The 7-bit ASCII Character Set
With the possible exception of NIL, all unique identifiers
in the range of zero (0) to one hundred twenty-seven (127) map directly
to the corresponding 7-bit ASCII character. This presents a basis
alphabet for definitions in the knowledge base. Other alphabets may
be supported in a knowledge base, but are not predefined by this proposal.
-
POS
The POS atoms unique identifier is used as an attribute
index by the dimension compound. The POS atom is used to represent
succession in an ordering.
-
NEG
The NEG atoms unique identifier is used as an attribute
index by the dimension compound. The NEG atom is used to represent
precession in an ordering.
-
PARENT
The PARENT atoms unique identifier is used as an
attribute index by the tree compound. The PARENT atom is used to
represent hierarchical containment.
-
REF
The REF atoms unique identifier is used as an attribute
index by all the components. The REF unique identifier is used by
compound backbone structures to refer back to the concepts they encapsulate.
-
TIME
The TIME atom is reserved as a known root of a dimension
of atoms that order other atoms by their creation time.
-
The ENGLISH-AM Proposed Atom
Assuming an initial forum of English speakers familiar
with American conventions of spelling and syntax, the ENGLISH-AM atom would
represent the concept of the American English language. The atom
would also double as the root atom of a dictionary used to map 7-bit ASCII
strings onto the conceptual atom for the corresponding American English
word. The dictionary atoms and the corresponding American English
word atoms would compose the American English subspace, defined below.
-
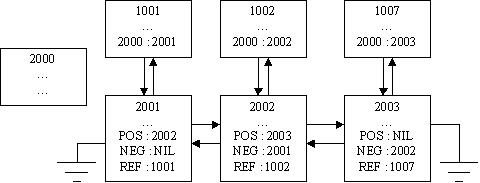
Dimension Characteristics.
The dimension compound is made up of a set of atoms
that are ordered by a set of backbone atoms. The following illustrates
the structure of a dimension.
Dimensions may be continuous or discontinuous. A continuous dimension
is a dimension where there are no gaps in the backbone. A discontinuous
dimension is one where the backbone may have several gaps where there
are multiple head nodes. The dimension places the following minimum requirements
on a dimension:
-
The Dimension Root Atom.
The dimension root atom exists primarily to reserve
a unique identifier for mapping a concept to its place in the dimension
backbone. The dimension root is able to contain more information
(such as the documenting the intention of the dimension, or referencing
the UIDs of the first and last backbone atoms,) but is only required to
exist in the dimension elements.
-
The Dimension Backbone.
The atoms that compose the dimension backbone must
map the UID of the POS and NEG reserved atoms. A head atom will map
the NEG atom to NIL. A tail atom will map the POS atom to NIL.
In all other cases, both the POS and NEG atoms must map to another atom
in the backbone. For any two atoms in the backbone, if an atom is
mapped by another atom via POS, the atom must map from NEG to the referring
atom. Dimensions may also be circular and therefore have no head
or tail atoms. Backbone atoms must also map the REF atom to an atom
that maps from the dimension root to the backbone atom.
-
The TIME Reserved Dimension.
The TIME reserved dimension is used to store the
creation time and order of atoms in a space. The TIME reserved dimension
uses the TIME reserved atom as its root. When an atom is created,
it may map from the TIME reserved atom to a new atom in the TIME dimension
backbone. The root node of the TIME dimension should map from REF
to the UID of the tail atom in the backbone. The root nodes map
is then updated to reference the new atom in the dimension, and the new
backbone atom and the old tail atom are made to map to each other (where
the old tail maps from POS to the new tail, and the new tail maps NEG to
the old tail.) The new tail backbone atom is set to map REF to the
originating atom, and the backbone atom is optionally defined as a 7-bit
ASCII string that uses the UTC format defined in [RFC822].
Note that not providing a UTC time for a backbone atom may cause incorrect
ordering if spaces are merged.
-
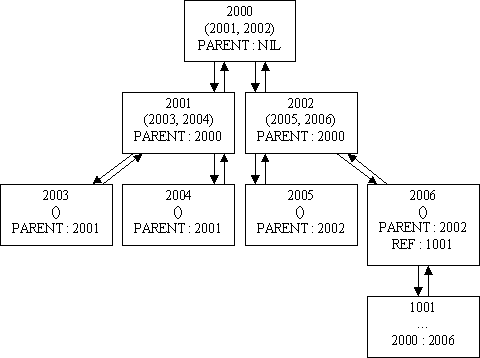
Tree Characteristics.
The tree compound is similar to the dimension in
that it has a backbone structure of atoms that are required to follow certain
rules. The tree compound captures a hierarchy by allowing an atom
to reference an arbitrary number of subordinate atom UIDs. The following
diagram shows a tree backbone along with one atom that is referenced by
the tree:
-
The Tree Backbone Atoms.
The tree backbone atoms contain subordinate atoms
in the tree by having the subordinate atoms UIDs in their definition
vector. Backbone atoms that have no subordinates, also known as leaf
nodes in data structure terminology, will have empty definition vectors.
If the order of the child nodes is important, then the ordering of their
UIDs in the definition should follow the intended ordering of children.
Tree backbone atoms may refer to other atoms in a space by mapping from
REF to a target atom.
-
The Tree Root Atom.
The root atom of the tree is distinguished as being
the only atom in the tree backbone that does not refer to a parent atom.
The root node of a tree should map PARENT to NIL.
-
Atoms Referenced by a Tree.
Atoms referenced by a tree are not required to refer
to the backbone atom. However, in the event that knowledge of such
relationships is desired, the referenced atom should map from the trees
root UID to the referring backbone atom.
-
Dictionary Characteristics.
The dictionary compound uses a backbone of atoms
that use the mapping component of atoms to create a data structure known
a trie [Bently and Sedgewick]. Using a trie,
vectors of UIDs may be mapped onto various atoms in a space. The
dictionary backbone atoms are navigated by mapping from individual UIDs
of a contained vector to dictionary atoms. When the last UID of a
contained vector is mapped, the resultant node is called a terminus atom.
The following illustration shows a dictionary that maps the UID vector
(c,a,r) to UID 3001, and the UID vector (c,a,t) to UID 3002
(where the c represents the UID for the lower case c 7-bit ASCII
character.).

-
The Dictionary Root Atom
As in other compounds, the root atom provides a
known UID for referenced atoms to use for mapping back to the compound
backbone. Additionally, root atoms are the starting point for any
mapping traversal of the dictionary backbone. The dictionary root
atom should map the UID of PARENT as well as REF to NIL.
-
The Dictionary Backbone Atom.
The dictionary backbone atoms, in addition to the
root atom, map from UIDs in what may be called the dictionarys alphabet
to other atoms in the backbone. Backbone atoms mapped by other dictionary
atoms should in turn link to the referring atom by mapping from PARENT
to the referring atom. Finally, the definition vector for a backbone
atom should contain a single UID. The sole UID in a backbone atoms
definition should be the UID that the parent atom uses to map the backbone
atom (this allows words in the dictionary to be generated from knowing
only the reference atom and the dictionary root atom.)
-
The Dictionary Reference Atoms.
The dictionary reference atom is used to buffer
the dictionary from the root concepts it maps. The reference atom
must map from the dictionary root atom UID to the referring backbone atom.
-
The ENGLISH-AM Proposed Dictionary
The ENGLISH-AM proposed dictionary would be a dictionary
that maps an authoritative set of UID vectors of American English words
(represented by their 7-bit ASCII strings) onto reference atoms.
The reference atoms would be defined using UID vectors of their ASCII definition
strings mixed with UIDs of other definitions. Potential sources
of words and definitions may be obtained from such projects as DICT.orgs
FILE project [DICT.ORG] or Princetons WordNet [WordNet].
-
Space Characteristics.
The collections of atoms that compose a space simply
place the following constraints on the space data structure: it should
have some means of indexing atoms by UID, and it should have some means
of containing the basis data structures used by atoms. The follow
subsections discuss two possible data storage means for a NOI space.
-
The Space as a XML Document.
The following is the body of the XML (extensible
markup language) DTD (document type definition) for a NOI space document.
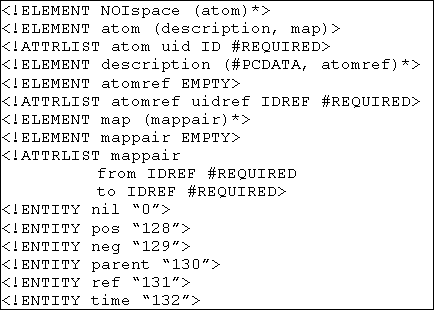
The root element of a NOI space is NOIspace. The NOIspace element
will contain all atoms in the space, where atoms contain their UID, description
text and their map. Atom UIDs use the XML ID attribute type, which
helps ensure the UID for each atom is unique under the XML specifications
validity constraints [XML]. Note that the UID
number may take any form that is supported by reader applications (which
can always map onto integers, regardless,) however, writer applications
are strongly recommended to output an integer numeral. The following
is a XML representation of a tree compound (with referenced node:)
<NOIspace>
<atom uid=1000>
<description>This is some text for the
description of atom 1001.</description>
<map>
<mappair from=2000 to=2002/>
</map>
</atom
<atom uid=2000>
<description>
<atomref uidref=2001>
<atomref uidref=2002>
</description>
<map/>
</atom>
<atom uid=2001>
<description/>
<map>
<mappair from=&parent; to=2000/>
</map>
</atom>
<atom uid=2002>
<description/>
<map>
<mappair from=&parent; to=2000/>
<mappair from=&ref; to=1001/>
</map>
</atom>
</NOIspace>
-
The Space as a Binary Database.
The following section shows a possible binary representation
of a NOI space as contained in a SQL database. The database will
consist of two tables, atoms and maps. These two tables are defined
in MySQL [MySQL] as follows:
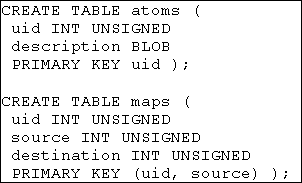
Using this format, UIDs are limited to the set of 32-bit unsigned
integers. The value of these integers is unambiguous for any given
database using data files it created. The primary issue for the given
format is the storage format of vectors of UIDs. While the easiest
solution would be to use the description column in the atoms table to hold
arrays of 32-bit integers, this would cause each 7-bit ASCII character
in a description to inflate in size from one byte to four. For the
purpose of constraining memory consumption, UIDs are further constrained
to be 31-bit integers. The binary data held in the description column
is then encoded based on the setting of the most significant bit for the
first byte of a UID reference. If the most significant bit is zero
(0,) then the UID reference is a one byte, 7-bit ASCII reference.
If the most significant bit is one (1,) then the UID reference is a four
byte, 31-bit, unsigned little endian integer (where the least significant
byte is the last eight bits of the binary integer, and the most significant
bit of all 32-bits is ignored or masked if moving the value from 31-bit
to 32-bit storage.) The following diagram illustrates the binary
storage format of the description column:
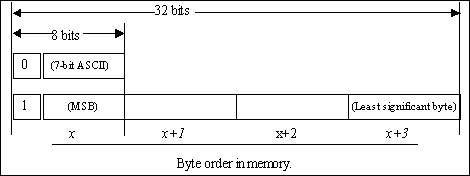
-
Operations.
The following section defines an abstract algebra
for operations on data in the NOI architecture. Listed below each
operation name is an example UML construct for the member or operation.
-
Global Space
Global : Space
The global level defines a default space that contains
atoms on the current system. The global space is defined to be the
variable G.
-
New Atom
newAtom(s : Space = Global) : Atom
The new atom operator will create an atom in the
parent space with a new UID value. The new atom will have an empty
definition vector and map everything to NIL (see the cross product operator.)
The new atom operator is represented as new(s), or new() for a new
atom in the global space.
-
Get Atom
getAtom (u : UID, s : Space = Global) : Atom
Get an atom from space s, by its UID u. Get
Atom is an infix asterisk operator. Example: s*u, where s is optional,
making *u the same as G*u.
-
Get UID
getUID (a : Atom) : UID
Get a UID from atom a. Get UID is a prefix
operator that uses the sharp symbol, #. Example: #a.
-
Get Content
getContent (a : Atom) : LIST<UID>
The get content operator returns the definition
UID vector of an atom, a. The operator is represented as a postfix
() after the symbol for the argument to the operator. Example:
a().
-
Set Content
setContent (a : Atom, v : LIST<UID>) : void
The set content operator replaces the definition
of atom a, with the UID vector v. The set content operator is represented
by a get content operation on the left hand side of an assignment operator
followed by the UID vector. Example: a() = v.
-
Cross Product
crossProduct (a : Atom, u : UID) : UID
The cross product operation may also be considered
to be a map lookup, where the map of atom a is referenced from UID u.
Where no mapping from a specified UID exists, the cross product will return
the UID of the NIL reserved atom. The cross product uses the infix
cross operator, ×, and is right associative (where cross products
are evaluated from right to left.) Example: a×u, a0×a1×u
= (a0×(a1×u)).
-
Set Mapping
setMapping (a : Atom, u : UID, v : UID) : void
The set mapping operation sets the return UID of
a cross product of atom a, and UID u, to a new value UID v. If the
The set mapping operator is an infix combination of the cross product operator
× and the assignment operator =. Example: a×u =
v.
-
Compress
compress (v : LIST<UID>, d : Atom) : LIST<UID>
The compress operator compresses the UID vector
v, using the dictionary specified by the root node d, returning a new list
of UIDs. An algorithm for the compress operator is shown below:

-
Expand
expand (v : LIST<UID>, d : Atom) : LIST<UID>
The expand operator expands the UID vector v, using
the dictionary specified by its root node d, and returns a new list of
UIDs. Expansion is a process that substitutes UIDs in the input
vector with UID vectors mapped in the input dictionary. Expansion
is accomplished by iterating over each UID in v, referencing the atom a
using its UID from v, mapping a from the dictionary root UID #d to the
trie backbone, looking up the tree trie backbone parent chain to get a
replacement vector, and then substituting the original UID in v with the
replacement vector. The resulting algorithm is shown below:

The expansion operation is the infix greater than operator, >, and
is left associative. Example: v>d, v>d0>d1 = ((v>d0)>d1).
-
Vectors and Dot Products
uidVector (inputString : LIST<UID>, dimensionRoot : Atom) : LIST<INT>
normalize (v : LIST<INT>) : LIST<FLOAT>
dotProduct (a : LIST<INT>, b : LIST<INT>) : FLOAT
dotProduct (a : LIST<FLOAT>, b : LIST<FLOAT>) : FLOAT
Vector math is defined for the purpose of comparing
atom content.
The UID vector contained by an atom may be converted
into a vector of UID counts (also referred to as a concept vector) using
the uidVector operation. The first operand to this operation is a
vector of UIDs. The second operand to the uidVector operation is
the head node of a dimension that references only the atoms whose UIDs
should be counted in the vector. This allows limiting the size of
the output vector, which may be as large as the highest defined UID in
the global space. If the second operand is the NIL atom, then all
UIDs are counted, and the count placed in the output vector at the position
indexed by the UID. Otherwise, the output vector is indexed based
on UID order in the input dimension. The uidVector operator is the
forward slash, /, and has no associative properties since the type of
the result of the operation is incompatible with either operand.
Example: a0()/a1.
A vector of integers, v, may be normalized into
a vector of floating point numbers that have the same proportions as the
input vector, but sum to one (1.0.) A vector flanked by the | operands
will be normalized. Example: |v|.
The dot product of two vectors of either integers
or real values is the result of the sum of products of the two vectors.
The sum of products is the result of v0[0] * v1[0] + v0[1] * v1[1] +
+ v0[n] * v1[n], where n is the maximum size of the two vectors, and undefined
regions of vectors are equal to zero. The dot product is represented
using the infix operator. Example: v0 v1.
-
Spatial Merge
merge (target : Space, source : Space) : Atom
The spatial merge is the addition of one space of
atoms to another. The target space is modified to contain an isomorphic
set of atoms contained by the source space. The source space is unaltered
by the merge. Where the target space is initially of size m, and
the source space is of size n, after the merge is performed, the target
space will be of size m+n. UID collisions between spaces are handled
by the creation of new UIDs in the target space. The operator returns
a key atom in the target space that maps from the UID of each atom in the
source space, to the UID of the resulting atom in the target space.
If the two spaces are not disjoint (i.e. they contain atoms that are identical
in UID, content and mapping,) the target space will contain duplicate data,
wasting space. Before the copied atoms are added to the target space,
the UIDs they reference in both their contents and their mappings are
translated according to the mapping of the key atom. The infix <=
operator is used to denote a spatial merge of once space to another.
Example: S0<=S1.
-
Applications
The following are some speculative applications
that interface with a network of ideas. Details of the architecture
and usage of these applications is outside the scope of this document,
and will be covered in another publication.
-
Atom Based Viewers and Editor
A network of ideas facility requires the ability
to view and edit content held in the database. The most basic entity
in the database is the atom. Hence, a basic viewing application for
a network of ideas would allow the content and map of an atom to be displayed
to a user. The viewer would decompress content UIDs to an entirely
7-bit ASCII representation, but still allow the user to view (or navigate
to) the atom for the UID. The viewer would also allow navigation
of the atoms map elements, either transitioning to the key UID content
or the target UID content. An atom-based editor would allow the content
and mapping of the atom to be modified, and new atoms to be generated.
The editor would facilitate the implicit linking of flat 7-bit ASCII text
to other UIDs by allowing the user to define a stack of dictionaries that
would be used to compress the atoms content into a string of UIDs.
The atoms map would also be available to create, modify, or remove mappings
from one UID to another. UIDs in the mapping would also be selectable
based on the keys in the dictionaries used to compress the atom content.
-
Visualization
Database content visualization applications could
be used to graphically depict neighborhoods of related concepts based
on the number of links between atoms and the minimum number of edges between
two atoms. Visualization of the larger database could also be employed
as a front end for navigation of the atoms in a concept space.
-
Compression
By taking words and groups of words, and reducing
their byte representation to a number, a network of ideas facility is capable
of containing electronic documents in a potentially more compressed form.
Several factors may determine the degree of compression within a database.
First, the size of the number representation in comparison to the size
of the basis alphabet may cause data sizes to increase instead of decrease.
In the current proposal, a 32-bit number is used to represent a word, and
will result in a space increase where the number replaces a word of three
characters or less. Therefore, the second factor in the amount of
compression achieved in a document is the average word size in characters.
The third factor is the frequency (and completeness) of words and phrases
in the sets of dictionaries used to compress the document.
-
Information Publishing and Collaboration
Using a set of network based viewing and editing
tools, online content and collaboration may be done using the network of
ideas. The architecture for such an environment would follow a simple
three-tier system consisting of a client interface that connected to a
content server that obtains atom content and mappings from a database server.
One obvious choice for the network interfaces would use an HTML viewer
to connect to an HTML server that provided viewer and editor functionality
stored in server side scripts. The scripts embedded in the servers
HTML documents would fetch, display and modify a database over a second
network connection (such as a client accessing PHP scripts [PHP]
on a HTML server that connected to a MySQL server [MySQL].)
-
Agent Based Navigation
In a feature related to the compression aspect of
a network of ideas, the reduction of words and phrases to enumerations
has the potential to simplify the design of database agents. Specifically,
agents may use sparse arrays of UID counts for the purpose of automated
content grading. Additional graph structure metrics may assist in
automated graph navigation, or in the development of search and moderation
heuristics.
-
Extensions to the Network of Ideas
In order to reduce the scope and complexity of the
network of ideas proposal, several options that would enhance the applicability
and functionality of a network of ideas facility were neglected.
-
Internationalization
By standardizing on 7-bit ASCII as the basis alphabet
for network of ideas data, the network of ideas removes the possibility
of non-Western character sets (such as Arabic, Japanese, or Cyrillic character
sets) from being supported at a fundamental level by its facilities.
In order to employ a multi-byte character set, the network of ideas proposal
would have to reserve UIDs for the numerical values of these character
sets. Under the current proposal, these character sets would have
to employ a mapping to a known set of UIDs, defined by one facility, but
not necessarily honored by other facilities. Furthermore, the proposal
neglects to define how one cultural dictionary may reference a shared set
of atoms without conflict. By providing such a schema, network of
ideas facilities would be able provide automated language translation at
some level (granted that unless a great deal of phrase mapping had been
done between two languages, the translations grammar would not be correct.)
-
Infinite UID Space
The binary data format given in the database
data specification restricts a network of ideas facility to a limited
number of atoms. Specifically, the maximum number of UIDs in a space
using the 7/31-bit binary numbering is 2^31+2^7 (2,147,483,776 UIDs.)
In a community of 150 users, this grants each user the ability to create
approximately 14,316,557 UIDs. Over a 20 year period, each user
would have to reserve a UID once every 1.36 minutes for the system to run
out of UIDs. However, such a system would obviously not scale to
a larger user base (such as the Internet user base,) over a larger time
frame (all of human history.) Streams of UIDs would require employment
of integer length encoding. One such scheme would be to use the most
significant bit of each byte as a terminator bit, where the most significant
bit of each byte is set except for the byte containing the least significant
seven bits.
-
Networking
The current proposal is based on a centralized facility
which primarily raises issues related to peering. No scheme is outlined
for sharing information between facilities other than detailing the mechanics
of a spatial merge. The issue of how separate facilities will know
about one other and how they will manage maps between their disparate concept
spaces is not currently addressed. Facility peering raises the larger
issue of how the data of a facility could be distributed across several
network stations. Extensions of the current proposal should add such
features as data peering and redundancy over a network.
-
Works Cited